
从「技能散落各处」到 monorepo:一个人管 9 个 bots 的 skill 版本控制实录
/ 8 min read
Table of Contents
代码版本不一致,程序会崩。AI skill 版本不一致,bot 会「隐隐地不对」——这比崩更可怕。
用 ClawdBot 的第三个月,某天我让两台机器上的 bot 处理同一篇文章,结果明显不一样。去查才搞清楚——Tachikoma 的 humanizer skill 升级了,Lacus 还在用一周前的旧版本,中间加了七条规则。
没有报错,没有通知。就这么静默地跑着。
那一刻我意识到:我管的 9 个 AI,它们的技能(skill)是活的——会演化,会分叉,会漂移。这是个新问题,没有最佳实践,我也没找到其他公开案例。
技能为什么会分叉
代码版本不一致,通常是粗心。AI skill 的分叉不太一样。
skill 是自然语言写的指令,描述「怎么做某件事」,不是「执行什么逻辑」。这意味着两件事:
第一,skill 会被主动修改。 某个 bot 在处理某类任务时发现旧的写法不够准,就地改了。改得有道理,但这个改动留在了它自己的 workspace 里,没有传播出去。
第二,skill 会被 bot 自己创造。 Lucius 在处理社区问题时,自己摸索出一套工作方式,产生了 lucius-autonomy-pm 这个 skill,没有经过任何 review,也没有人知道它什么时候长出来的。
代码分叉有 merge conflict。skill 分叉只有行为漂移。
搞了一圈,没有现成答案
搜了一圈。什么都没有。
「multi-bot skill management best practices」——零结果。跑 9 个 bot 的人极少,我没找到其他公开案例。这不是有最佳实践的领域——它还太新了。
只有一个基础机制是清楚的:OpenClaw 的 skill 有优先级层级。官方文档写明的:同名 skill,高优先级覆盖低优先级。这是解法的起点。
workspace/skills/ ← 最高(bot 专属)~/.openclaw/skills/ ← 次高(机器共享)skills.load.extraDirs ← 最低(可指向 git clone)bundled skills ← 兜底从「技能散落各处」到统一管理
建了一个 git repo:bot-skills,按用途分 namespace:
skills/ common/ ← 通用工具,所有 bot 都能用 velocity1/ ← 个人生产力 chuhaiqu/ ← 出海去社区运营 lucius/ ← Lucius AI 产品 yxyc/ ← Luffy + Chopper 共享 public/ ← Crabby 对外用户可触发每个 bot 有一个 manifest.txt,声明自己要订阅哪些 namespace。distribute.sh 按 manifest 分发——Crabby 拿不到 velocity1 里的 skill,不靠人记住,脚本拦截。
这个结构,本质上是 OOP 的 package visibility 用 shell 脚本实现的版本:
common/ = public method(所有人都能调用)org/ = package-private(只有同 org 的 bot 能访问)manifest.txt = interface contract(声明依赖,不声明实现)distribute.sh = 访问控制(脚本强制,可被绕过——这是诚实的说法)Crabby(面向真实用户的公开 bot)试图拿 velocity1 里的 skill?distribute.sh 直接拦截。不靠人记住规则,写死在逻辑里。权限管理不应该靠纪律,应该靠结构。
PR review:最难的部分
有了技能库之后,新问题:技能更新后怎么 review?
skill 是 Markdown 文件,diff 很好出,但读 diff 很难。9 个 bot 对同一个 skill 各有各的版本,怎么一眼看出「这次更新,每个 bot 会得到什么、失去什么」?
第一次尝试:把所有 bot 的同名 skill 塞进一个 PR,生成 PROPOSED_SHARED.md + 每个 bot 的 DIFFS.md。结果所有 bot 的 diff 全混在一起,还是看不清楚。
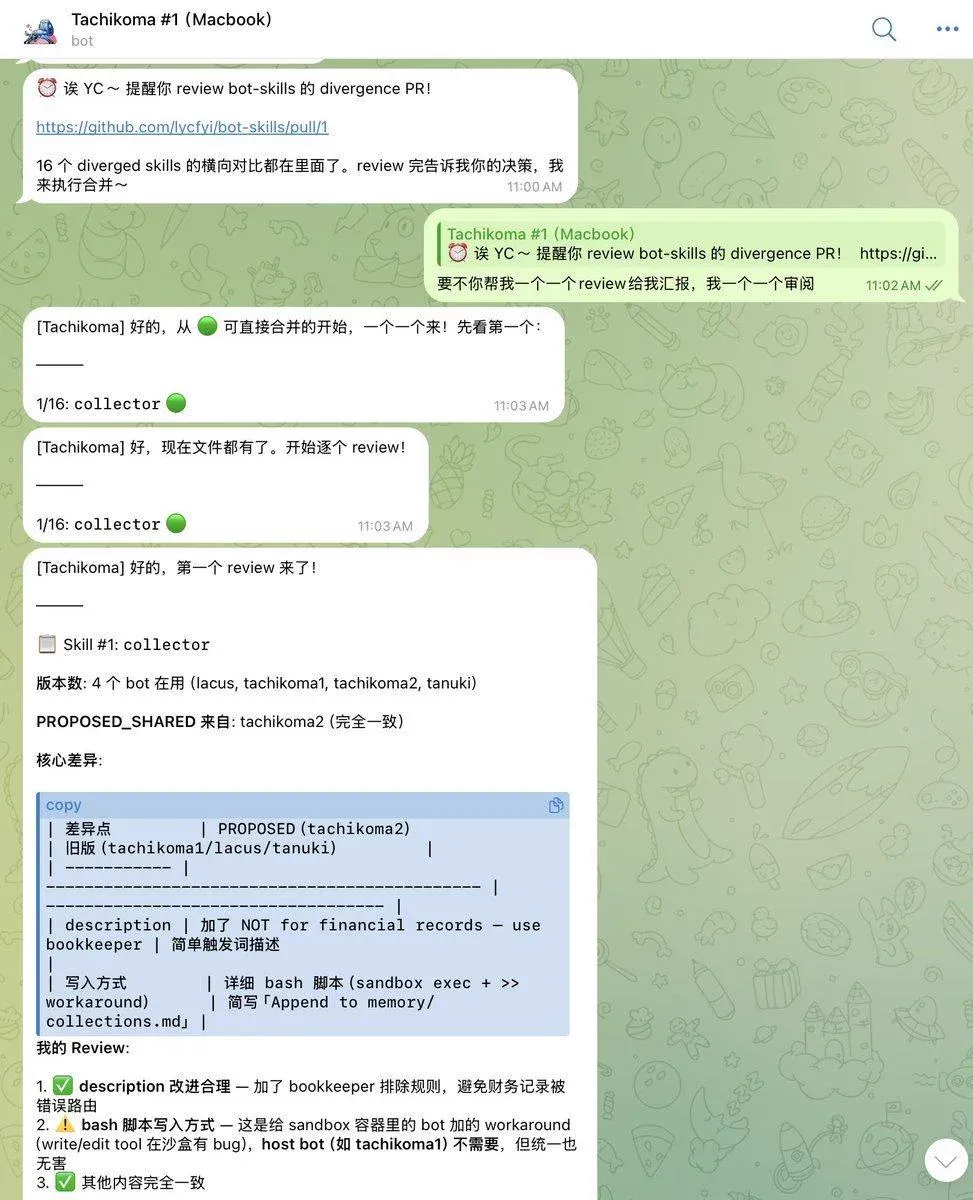
后来想明白了:shared baseline + per-bot 独立 PR。
先把最小公分母版本 merge 进 main,再给每个 bot 开一个 PR。这个 PR 的 diff 就是「这个 bot 相对于 shared 的增量」——它的个性化版本和 shared 的差在哪,一眼清楚。
技能的逆流:bot 自创的怎么办
除了「往 bot 推技能」,还有另一个方向。
collect.sh 扫描所有 bot 的 workspace,找出不在 manifest 里的 skill,收到 .inbox/ 等待 review。bot 在运行中摸索出的新工作方式,不会野生生长,不会消失,进入一个可以被审查的流程。
两个方向跑通后:
distribute.sh → 技能库 → bot(中央 → 边缘)collect.sh ← bot 自创 → .inbox/(边缘 → 中央)这不是 DevOps,这是放牧。你在管理有自主性的、会自己跑的东西。

还没解决的问题
这套系统有效,但不完整。
版本锁定。 每个 bot 只知道「我用 humanizer」,不知道「我用哪个版本」。skill 更新后 bot 静默切换,没有通知,没有回滚。代码世界有 package-lock.json,skill 世界还没有。
语义漂移检测。 版本号一样的 skill,内容可能已经被改过。代码有 hash 校验,skill 目前只靠文件对比。版本号一样,内容被改过——这不是 bug,这是语义漂移。
依赖关系。 content-pipeline 依赖 drafter、goldsmith、critic。这些依赖只存在于自然语言描述里,没有机器可读的 manifest。某个依赖缺失时,bot 静默降级,不报错。你的 bot 不是坏了,它只是变笨了。
代码世界有 git blame。AI skill 世界还没有。这就是现在。
下一步计划
短期内要做两件事。
一是给 collect.sh 加 divergence report:每次运行输出哪些 bot 的技能和 shared 版本有差异,差异多大。把隐性分叉变成可见数据。
二是给 manifest 加版本字段:humanizer@2.1。distribute 时如果目标版本比现有版本旧,跳过,不覆盖。bot 可以钉住一个它信任的版本,不跟最新。
再往后,可能是轻量的 skill registry——语义化版本号,声明依赖,自动解析冲突。值不值得做,要看实际痛点有多重。
AI 技能的演化管理,现在还是一片空白。这篇记录的是我目前摸出来的那一段路,不是最终答案。
如果你管着超过 3 个 bot,现在就去查:它们的技能版本一致吗?答案可能会吓你一跳。