
From Scattered Skills to Monorepo: One Person Managing Skill Version Control Across 9 Bots
/ 5 min read
Table of Contents
Code version mismatch crashes your program. AI skill version mismatch makes your bot behave “subtly wrong” — which is worse.
In my third month running ClawdBot, I had two bots process the same article on different machines. The results were noticeably different. Turned out Tachikoma’s humanizer skill had been upgraded — Lacus was still running a version from a week prior, seven rules behind.
No error. No notification. Just silently running.
That’s when I realized: the 9 AI agents I manage have living skills — they evolve, fork, and drift. It’s a new problem. No best practices exist. I couldn’t find a single other public case study.
Why skills diverge
Code version drift is usually carelessness. AI skill divergence is different.
Skills are natural language instructions — they describe how to do something, not what logic to execute. This means two things can happen:
First, skills get actively modified. A bot finds its existing approach insufficient for a task and edits the skill in place. The edit makes sense, but it stays in that bot’s workspace and never propagates.
Second, bots create new skills themselves. Lucius developed its own community management approach over time, generating a lucius-autonomy-pm skill with no review, no audit trail, and no timestamp anyone could find.
Code forks produce merge conflicts. Skill forks produce behavioral drift.
I searched. Nothing exists.
“Multi-bot skill management best practices” — zero results. Very few people run 9 bots. No public case studies. This field doesn’t have best practices yet. It’s too new.
One foundation was clear: OpenClaw’s skill priority system. Same-name skills at higher priority override lower ones. That’s the mechanism to build on:
workspace/skills/ ← highest (bot-specific)~/.openclaw/skills/ ← mid (machine-wide)skills.load.extraDirs ← lowest (can point to git clone)bundled skills ← fallbackFrom scattered skills to a central repo
I built a git repo: bot-skills, organized by namespace:
skills/ common/ ← shared tools, available to all bots velocity1/ ← personal productivity chuhaiqu/ ← community ops lucius/ ← Lucius AI product yxyc/ ← Luffy + Chopper shared public/ ← user-facing Crabby skillsEach bot has a manifest.txt declaring which namespaces it subscribes to. distribute.sh enforces this — Crabby can’t pull velocity1 skills, not by convention, but by hardcoded logic.
The structure maps directly to OOP package visibility, implemented in shell:
common/ = public method (callable by anyone)org/ = package-private (same-org bots only)manifest.txt = interface contract (declares dependencies)distribute.sh = access control (enforced by script, not compiler)Permissions shouldn’t rely on discipline. They should be structural.
PR review: the hard part
With a central repo established, the next problem: how do you review skill updates?
Skills are Markdown files — diffing is easy, but reading diffs is hard. Each of 9 bots has its own version of the same skill. How do you see at a glance what each bot gains or loses from an update?
First attempt: stuff all bots’ versions of a skill into one PR, generate PROPOSED_SHARED.md + per-bot DIFFS.md. Result: everything mixed together, still unreadable.
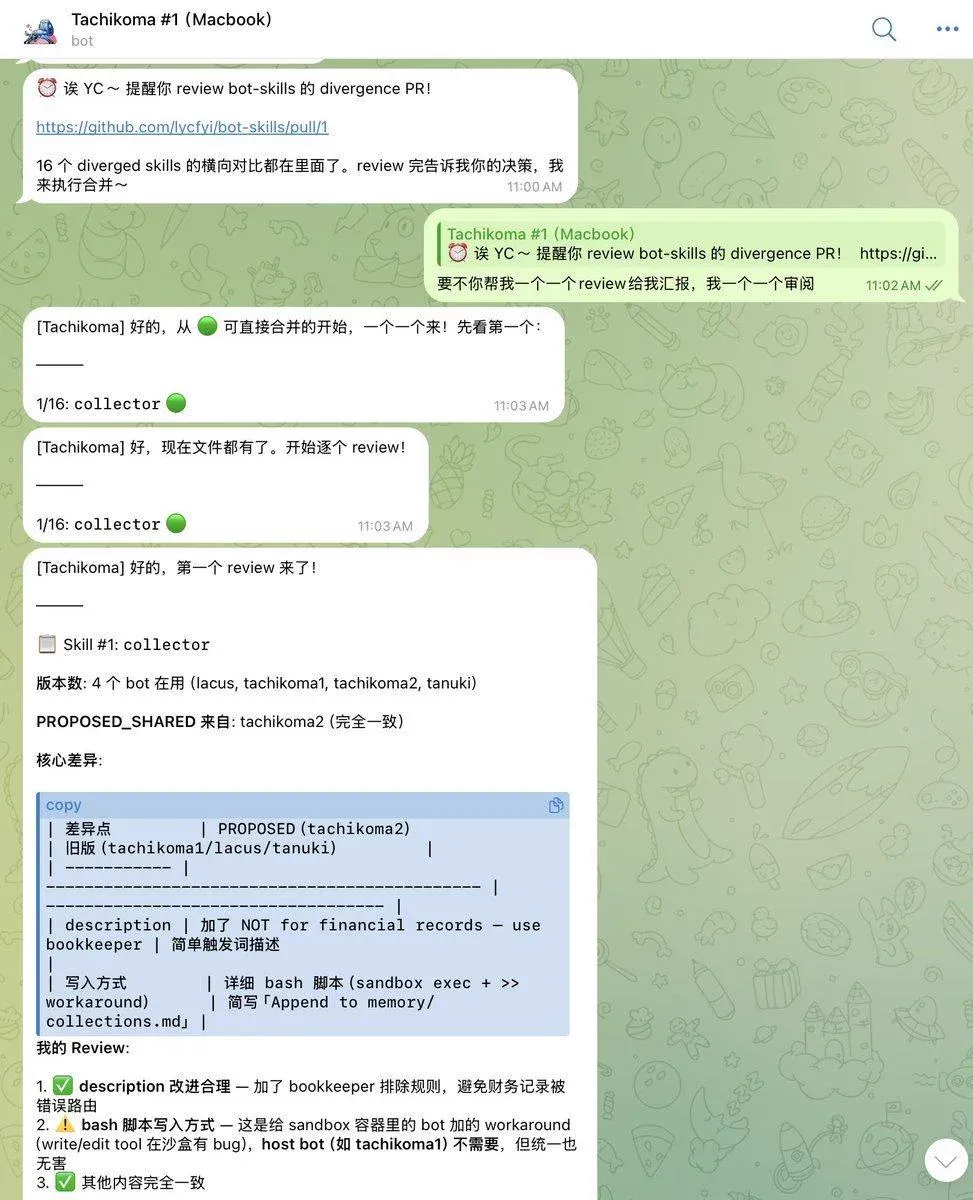
The fix: shared baseline + per-bot PRs.
Merge the minimum common version into main first. Then open one PR per bot. That PR’s diff shows exactly what that bot gains or loses relative to the shared version. Review one thing at a time.
The reverse flow: what about skills bots create themselves?
Pushing skills out is only one direction.
collect.sh scans all bot workspaces, finds skills not in any manifest, and pulls them into .inbox/ for review. Skills bots develop at runtime don’t get lost, but they don’t silently propagate either — they enter a reviewable process.
Two directions, both running:
distribute.sh → skill repo → bot (center → edge)collect.sh ← bot-created → .inbox/ (edge → center)This isn’t DevOps. It’s herding. You’re managing things with agency that run on their own.

Unsolved problems
The system works. But it’s incomplete.
Version pinning. Bots know “I use humanizer” but not “which version of humanizer.” Skills updates trigger silent switches — no notification, no rollback. Code has package-lock.json. Skills don’t yet.
Semantic drift detection. Same version number, different content (if someone edited the file without bumping the version). Code has hash verification. Skills currently rely on file comparison. Same version, different instructions — that’s not a bug, it’s semantic drift.
Dependency resolution. content-pipeline depends on drafter, goldsmith, critic. These dependencies only exist in natural language descriptions — no machine-readable manifest. A missing dependency triggers silent degradation, no error. Your bot isn’t broken. It just got dumber.
The code world has git blame. The AI skill world doesn’t. That’s where we are.
What’s next
Two things in the short term.
First: add a divergence report to collect.sh — output which bots’ skills differ from the shared version, and by how much. Make hidden drift visible.
Second: add version fields to manifests — humanizer@2.1. If the target version is older than what’s installed, skip rather than overwrite. Bots can pin to a version they trust.
Further out: a lightweight skill registry — semantic versioning, dependency declarations, automatic conflict resolution. Whether it’s worth building depends on how bad the pain gets.
AI skill lifecycle management is an open problem. This is what I’ve figured out so far. Not the final answer.
If you’re running more than 3 bots, go check now: are their skill versions consistent? The answer might surprise you.